The Verizon Data Breach Investigations Report (DBIR) is one of the most popular referenced security research documents. I feel like every other presentation I see contains quotes and references however have you ever wondered how accurate the data is? The people at Trail of bits took a look at the DBIR’s data quality and found a ton of areas that need improvement. They opened the post with the statement “If you follow the recommendations in the 2016 Verizon Data Breach Investigations Report (DBIR), you will expose your organization to more risk, not less”. Their original post can be found HERE.
The DBIR’s ‘Forest’ of Exploit Signatures
This question undermines the rest of the report. The DBIR is a collaborative effort involving 60+ organizations’ proprietary data. It’s the single best source of information for enterprise defenders, which is why it’s a travesty that its section on vulnerabilities used in data breaches contains misleading data, analysis, and recommendations.
Verizon must ‘be better.’ They have to set a higher standard for the data they accept from collaborators. I recommend they base their analysis on documented data breaches, partner with agent-based security vendors, and include a red team in the review process. I’ll elaborate on these points later.
Digging into the vulnerability data
For the rest of this post, I’ll focus on the DBIR’s Vulnerability section (pages 13-16). There, Verizon uses bad data to discuss trends in software exploits used in data breaches. This section wascontributed by Kenna Security (formerly Risk I/O), a vulnerability management startup with $10 million in venture funding. Unlike the rest of the report, nothing in this section is based on data breaches. It’s easy to criticize the analysis in the Vulnerabilities section. It repeats common tropes long attacked by the security community, like simple counting of known vulnerabilities (Figures 11, 12, and 13). Counting vulnerabilities fails to consider the number of assets, their importance to the business, or their impact. There’s something wrong with the underlying data, too.
It’s easy to criticize the analysis in the Vulnerabilities section. It repeats common tropes long attacked by the security community, like simple counting of known vulnerabilities (Figures 11, 12, and 13). Counting vulnerabilities fails to consider the number of assets, their importance to the business, or their impact. There’s something wrong with the underlying data, too.
Verizon notes in the section’s header that portions of the data come from vulnerability scanners. In footnote 8, they share some of the underlying data, a list of the top 10 exploited vulnerabilities as detected by Kenna. According to the report, these vulnerabilities represent 85% of successful exploit traffic on the Internet. Jericho at OSVDB was the first to pick apart this list of CVEs. He noted that the DBIR never explains how successful exploitation is detected (their subsequent clarification doesn’t hold water), nor what successful exploitation means in the context of a vulnerability scanner. Worse, he points out that among the ‘top 10’ are obscure local privilege escalations, denial of service flaws for Windows 95, and seemingly arbitrary CVEs from Oracle CPUs.
Jericho at OSVDB was the first to pick apart this list of CVEs. He noted that the DBIR never explains how successful exploitation is detected (their subsequent clarification doesn’t hold water), nor what successful exploitation means in the context of a vulnerability scanner. Worse, he points out that among the ‘top 10’ are obscure local privilege escalations, denial of service flaws for Windows 95, and seemingly arbitrary CVEs from Oracle CPUs.
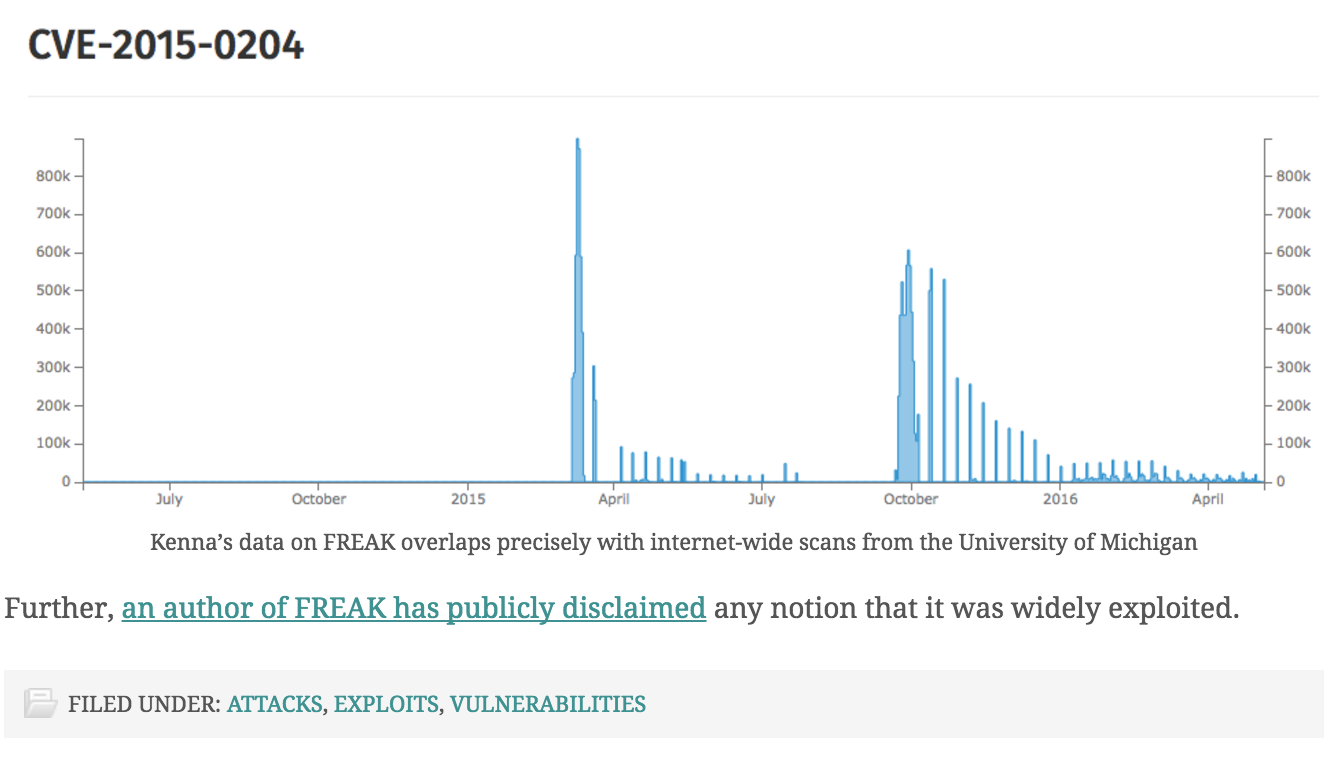
Rory McCune at NCC was the second to note discrepancies in the top ten list. Rory zeroed in on the fact that one of Kenna’s top 10 was the FREAK TLS flaw which requires network man-in-the-middle, a vulnerable server, a vulnerable client to exploit, and substantial computational power to pull it off at scale. Additionally, successful exploitation produces no easily identifiable network signature. In the face of all this evidence against the widespread exploitation of FREAK, Kenna’s extraordinary claims require extraordinary evidence.
When questioned about similar errors in the 2015 DBIR, Kenna’s Chief Data Scientist Michael Rohytman explained, “the dataset is based on the correlation of ids exploit signatures with open vulns.” Rohytman later noted that disagreements about the data likely stem from differing opinions about the meaning of “successful exploitation.”
These statements show that the vulnerability data is unlike all other data used in the DBIR. Rather than the result of a confirmed data breach, the “successful exploit traffic” of these “mega-vulns” was synthesized by correlating vulnerability scanner output with intrusion detection system (IDS) alerts. The result of this correlation does not describe the frequency nor tactics of real exploits used in the wild.
Obfuscating with fake scienceFaced with a growing chorus of criticism, Verizon and Kenna published a blog post that ignores critics, attempts to obfuscate their analysis with appeals to authority, substitutes jargon for a counterargument, and reiterates dangerous enterprise security policies from the report. The first half of the Kenna blog post moves the goalposts. They present a new top ten list that, in many ways, is even more disconnected from data breaches than the original. Four of the ten are now Denial of Service (DoS) flaws which do not permit unauthorized access to data. Two more are FREAK which, if successfully exploited, only permit access to HTTPS traffic. Three are 15-year-old UPnP exploits that only affect Windows XP SP0 and lower. The final exploit is Heartbleed which, despite potentially devastating impact, can be traced to few confirmed data breaches since its discovery.
The first half of the Kenna blog post moves the goalposts. They present a new top ten list that, in many ways, is even more disconnected from data breaches than the original. Four of the ten are now Denial of Service (DoS) flaws which do not permit unauthorized access to data. Two more are FREAK which, if successfully exploited, only permit access to HTTPS traffic. Three are 15-year-old UPnP exploits that only affect Windows XP SP0 and lower. The final exploit is Heartbleed which, despite potentially devastating impact, can be traced to few confirmed data breaches since its discovery.
Kenna’s post does answer critics’ calls for the methodology used to define a ‘successful exploitation’: an “event” where 1) a scanner detects an open vulnerability, 2) an IDS triggers on that vulnerability, and 3) one or more post-exploitation indicators of compromise (IOCs) are triggered, presumably all on the same host. This approach fails to account for the biggest challenge with security products: false positives. Flaws in the data
Flaws in the data
As mentioned earlier, the TLS FREAK vulnerability is the most prominent error in the DBIR’s Vulnerabilities section. FREAK requires special access as a network Man-in-the-Middle (MITM). Successful exploitation only downgrades the protections from TLS. An attacker would then have to factor a 512-bit RSA modulus to decrypt the session data; an attack that cost US$75 for each session around the time the report was in production. After decrypting the result, they’d just have a chat log; no access to either the client nor server devices. Given all this effort, the low pay-off, and the comparative ease and promise of other exploits, it’s impossible that the TLS FREAK flaw would have been one of the ten most exploited vulnerabilities in 2015.
The rest of the section’s data is based on correlations between intrusion detection systems and vulnerability scanners. This approach yields questionable results.
All available evidence (threat intel reports, the Microsoft SIR, etc.) show that real attacks occur on the client side: Office, PDF, Flash, Browsers, etc. These vulnerabilities, which figure so prominently in Microsoft data and DFIR reports about APTs, don’t appear in the DBIR. How come exploit kits and APTs are using Flash as a vector, yet Kenna’s top 10 fails to list a single Flash vulnerability? Because, by and large, these sorts of attacks are not visible to IDS nor vulnerability scanners. Kenna’s data comes from sources that cannot see the actual attacks.
Intrusion detection systems are designed to inspect traffic and apply a database of known signatures to the specific protocol fields. If a match appears, most products will emit an alert and move on to the next packet. This “first exit” mode helps with performance, but it can lead to attack shadowing, where the first signature to match the traffic generates the only alert. This problem gets worse when the first signature to match is a false positive.
The SNMP vulnerabilities reported by Kenna (CVE-2002-0012, CVE-2002-0013) highlight the problem of relying on IDS data. The IDS signatures for these vulnerabilities are often triggered by benign security scans and network discovery tools. It is highly unlikely that a 14-year old DoS attack would be one of the most exploited vulnerabilities across corporate networks.
Vulnerability scanners are notorious for false positives. These products often depend on credentials to gather system information, but fall back to less-reliable testing methods as a last resort. The UPnP issues reported by Kenna (CVE-2001-0877, CVE-2001-0876) are false positives from vulnerability scanning data. Similar to the SNMP issues, these vulnerabilities are often flagged on systems that are not Windows 98, ME, or XP, and are considered line noise by those familiar with vulnerability scanner output.

 It’s unclear how the final step of Kenna’s three-step algorithm, detection of post-exploitation IOCs, supports correlation. In the republished top ten list, four of the vulnerabilities are DoS flaws and two enable HTTPS downgrades. What is a post-exploitation IOC for a DoS? In all of the cases listed, the target host would crash, stop receiving further traffic, and likely reboot. It’s more accurate to interpret post-exploitation IOCs to mean, “more than one IDS signature was triggered.”
It’s unclear how the final step of Kenna’s three-step algorithm, detection of post-exploitation IOCs, supports correlation. In the republished top ten list, four of the vulnerabilities are DoS flaws and two enable HTTPS downgrades. What is a post-exploitation IOC for a DoS? In all of the cases listed, the target host would crash, stop receiving further traffic, and likely reboot. It’s more accurate to interpret post-exploitation IOCs to mean, “more than one IDS signature was triggered.”
The simplest explanation for Kenna’s results? A serious error in the correlation methodology.
Issues with the methodology
Kenna claims to have 200+ million successful exploit events in their dataset. In nearly all the cases we know about, attackers use very few exploits. Duqu duped Kaspersky with just two exploits. Phineas Phisher hacked Hacking Team with just one exploit. Stuxnet stuck with four exploits. The list goes on. There are not 50+ million breaches in a year. This is a sign of poor data quality. Working back from the three-step algorithm described earlier, I conclude that Kenna counted IDS signatures fired, not successful exploit events.
There are some significant limitations to relying on data collected from scanners and IDS. Of the thousands of companies that employ these devices -and who share the resulting data with Kenna- a marginal number go through the effort of configuring their systems properly. Without this configuration, the resulting data is a useless cacophony of false positives. Aggregating thousands of customers’ noisy datasets is no way to tune into a meaningful signal. But that’s precisely what Kenna asks the DBIR’s readers to accept as the basis for the Vulnerabilities section.
Let’s remember the hundreds of companies, public initiatives, and bots scanning the Internet. Take the University of Michigan’s Scans.io as one example. They scan the entire Internet dozens of times per day. Many of these scans would trigger Kenna’s three-part test to detect a successful exploit. Weighting the results by the number of times an IDS event triggers yields a disproportionate number of events. If the results aren’t normalized for another factor, the large numbers will skew results and insights. Finally, there’s the issue of enterprises running honeypots. A honeypot responds positively to any attempt to hack into it. This would also “correlate” with Kenna’s three-part algorithm. There’s no indication that such systems were removed from the DBIR’s dataset.
Finally, there’s the issue of enterprises running honeypots. A honeypot responds positively to any attempt to hack into it. This would also “correlate” with Kenna’s three-part algorithm. There’s no indication that such systems were removed from the DBIR’s dataset.
In the course of performing research, scientists frequently build models of how they think the real world operates, then back-test them with empirical data. High-quality sources of empirical exploit incidence data are available from US-CERT, which coordinates security incidents for all US government agencies, and Microsoft, which has unique data sources like Windows Defender and crash reports from millions of PCs. From their reports, only the Heartbleed vulnerability appears in Kenna’s list. The rest of the data and recommendations from US-CERT and Microsoft match. Neither of them agree with Kenna.
 Ignore the DBIR’s vulnerability recommendations
Ignore the DBIR’s vulnerability recommendations
“This is absolutely indispensable when we defenders are working together against a sentient attacker.” — Kenna Security
Even if you take the DBIR’s vulnerability analysis at face value, there’s no basis for assuming human attackers behave like bots. Scan and IDS data does not correlate to what real attackers would do. The only way to determine what attackers truly do is to study real attacks.
 Empirical data disagrees with this approach. Whenever new exploits and vulnerabilities come out,attacks spike. This misguided recommendation has the potential to cause real, preventable harm. In fact, the Vulnerabilities section of the DBIR both advocates this position and then refutes it only one page later.
Empirical data disagrees with this approach. Whenever new exploits and vulnerabilities come out,attacks spike. This misguided recommendation has the potential to cause real, preventable harm. In fact, the Vulnerabilities section of the DBIR both advocates this position and then refutes it only one page later.
 Recommendations from this section fall victim to many of the same criticisms of pure vulnerability counting: they fail to consider the number of assets, the criticality of them, the impact of vulnerabilities, and how they are used by real attackers. Without acknowledging the source of the data, Verizon and Kenna walk the reader down a dangerous path.
Recommendations from this section fall victim to many of the same criticisms of pure vulnerability counting: they fail to consider the number of assets, the criticality of them, the impact of vulnerabilities, and how they are used by real attackers. Without acknowledging the source of the data, Verizon and Kenna walk the reader down a dangerous path.
Improvements for the 2017 DBIR
“It would be a shame if we lost the forest for the exploit signatures.”
— Michael Rohytman, Chief Data Scientist, Kenna
This closing remark from Kenna’s rebuttal encapsulates the issue: exploit signatures were used in lieu of data from real attacks. They skipped important steps while collecting data over the past year, jumped to assumptions based on scanners and IDS devices, and appeared to hope that their conclusions would align with what security professionals see on the ground. Above all, this incident demonstrates the folly of applying data science without sufficient input from practitioners. The resulting analysis and recommendations should not be taken seriously.
Kenna’s 2015 contribution to the DBIR received similar criticism, but they didn’t change for 2016. Instead, Verizon expanded the Vulnerability section and used it for the basis of recommendations. It’s alarming that Verizon and Kenna aren’t applying critical thinking to their own performance. They need to be more ambitious with how they collect and analyze their data.
Here’s how the Verizon 2017 DBIR could improve on its vulnerability reporting:
- Collect exploit data from confirmed data breaches. This is the basis for the rest of the DBIR’s data. Their analysis of exploits should be just as rigorous. Contrary to what I was told on Twitter, there is enough data to achieve statistical relevance. With the 2017 report a year away, there’s enough time to correct the processes of collecting and analyzing exploit data. Information about vulnerability scans and IDS signatures don’t serve the information security community, nor their customers.
- That said, if Verizon wants to take more time to refine the quality of the data they receive from their partners, why not partner with agent-based security vendors in the meantime? Host-based collection is far closer to exploits than network data. CrowdStrike, FireEye, Bit9,Novetta, Symantec and more all have agents on hosts that can detect successful exploitation based on process execution and memory inspection; more reliable factors.
- Finally, include a red team in the review process of future reports. It wasn’t until the 2014 DBIR that attackers’ patterns were separated into nine categories; a practice that practitionershad developed years earlier. That technique would have been readily available if the team behind the DBIR had spoken to practitioners who understand how to break and defend systems. Involving a red team in the review process would strengthen the report’s conclusions and recommendations.
Be better
For the 2016 DBIR, Verizon accepted a huge amount of low-quality data from a vendor. They reprinted the analysis verbatim. Clearly, no one who understands vulnerabilities was involved in the review process. The DBIR team tossed in some data-science vocab for credibility, and a few distracting jokes, and asked for readers’ trust.
Worse, Verizon stands behind the report, rather than acknowledge and correct the errors.
Professionals and businesses around the world depend on this report to make important security decisions. It’s up to Verizon to remain the dependable source for our industry.
I’d like to thank HD Moore, Thomas Ptacek, Grugq, Dan Rosenberg, Mike Russell, Kelly Shortridge,Rafael Turner, the entire team at Trail of Bits, and many others that cannot be cited for their contributions and comments on this blog post.
UPDATE 1:
Rory McCune has posted a followup where he notes a huge spike in Kenna’s observed exploitation of FREAK occurs at exactly the same time that the University of Michigan was scanning the entire internet for it. This supports the theory that benign internet-wide scans made it into Kenna’s data set where they were scaled by their frequency of occurrence.